

(1)理解数据整理的目的,掌握数据整理的基本方法。
(2)能根据需求选择适当的工具整理数据。
(3)应用恰当的方法保护数据,理解对数据进行保护的重要意义,增强数据安全意识。

通过“关于种植大棚蔬菜的天气情况数据的整理”的项目体验与探究,了解数据整理的目的,能通过分析数据,找出数据中的存在的问题然后整理数据。

安装有python编辑器的可上网的电脑。

![]()
思考并回答以下问题:
![]()
我们已经知道天气情况是影响蔬菜生长的重要因素之一,了解天气情况对大棚蔬菜的种植和生长有着至关重要的作用,对提高蔬菜种植的控制能力具有十分重要的意义。针对“关于大棚蔬菜种植条件的研究”这个大项目,上节课我们一起已经为此采集了某地2018年全年的天气情况,准备通过分析这些数据,指导以后大棚蔬菜的种植工作。经过讨论观察,我们发现数据有以下问题:
(1)数据重复
(2)数据为空
(3)数据异常
(4)数据缺少
所以对采集的数据进行标准化整理是我们这节课需要解决的问题。我们可以使用Excel等软件或平台,但是使用Excel等软件会对源数据进行破坏,而且Excel对大数据处理效率也较低,为了克服这些困难,可以使用python语言中的pandas标准库对数据进行整理。
任务:使用python语言导入“天气情况_未整理.csv”文件,简单了解数据的情况。
微课1:安装库
操作建议:
df=pd.read_csv('天气情况_未整理.csv') #导入“天气情况_未整理.csv”文件
(1)了解DataFrame的二维表格的数据结构。
说明:Pandas中有两个重要的数据结构:Series和DataFrame 。
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同数据类型的数据。DataFrame既有行标签也有列标签。
如下图所示:

(2)理解DataFrame标签的意义和作用。
微课2:通过标签获取信息
使用行和列标签获取 DataFrame 的行、列或单个元素的信息
例如:获取“星期”列信息:df[[‘星期’]]
获取第2行信息:df.loc[[1]]
获取单个元素信息:df[‘星期’][1]
学生 | 实践活动(A、B、C) 注:A=非常符合,B=符合,C=不符合 | |
自评 | 教师评 | |
理解DataFrame | ||
理解DataFrame标签 | ||
使用标签获取数据信息 | ||
![]()
什么是“脏数据”。
答案:“脏数据”是指源系统中的数据不在给定的范围内或对于实际业务毫无意义,或是数据格式非法,以及在源系统中存在不规范的编码和含糊的业务逻辑。包括数据重复、数据为空、数据异常和数据缺少等情况。
任务:整理“脏数据”
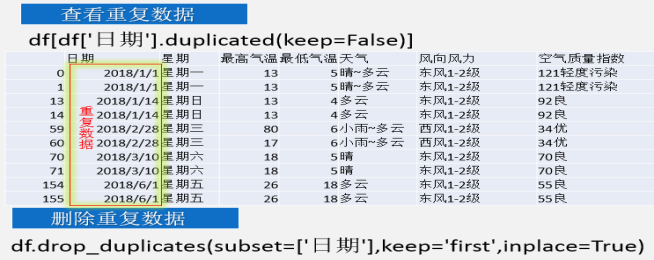
(1)我们怎样查看数据是否重复,怎样去除重复数据。
微课3:整理重复数据
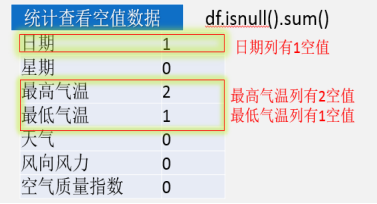
(2)查看是否有空值,对空值有哪些处理方式,怎样对空值内容重新录入。
微课4:整理空值数据

(3)怎样判断哪些是异常的数据,对异常的数据的处理方式有哪些,怎样选择合适的方式处理异常数据。
微课5:整理异常数据

(4)怎样增加正确的数据。
微课6:整理缺失数据

学生 | 实践活动(A、B、C) 注:A=非常符合,B=符合,C=不符合 | |
自评 | 教师评 | |
理解“脏数据” | ||
查看“脏数据” | ||
整理“脏数据” | ||
![]()
任务:根据提供“weatherprocessing.py”程序对数据进行分析和整理。数据整理完成后,简单查看各种统计数据,确保数据经过整理,已经标准化并且导出整理好的数据进行保存。并思考以下问题:
(1)怎样才算是标准化的数据
(2)怎样导出数据
操作建议:
(1)查看数据简单统计信息:df.describe()
(2)对整理好的数据进行导出保存: df.to_csv('天气情况_已整理.csv',encoding='utf_8_sig')
![]()
任务:安全的保存数据。并思考以下问题:
(1)数据安全的威胁主要有哪些?
答:计算机病毒,黑客攻击,数据存储介质损坏和个人失误等。
(2)我们怎样安全的保护数据?
答:移动存储设备备份,云存储备份和数据加密等。
(3)云存储备份操作
答:使用百度网盘上传备份整理好的数据。
参考“百度网盘使用图解教程.doc”
![]()
每个小组根据南水北调工程项目制定的项目规划,整理相关数据。
1.各组根据采集的相关水资源数据,进行异常数据处理,删除重复数据,增加缺少的数据,填写数据中的空值。
2.将数据保存为CSV格式文件。


